はじめに
「C言語入門」...といってもC言語自体をすべて解説するつもりはありません。
C言語を学ぶ上で理解しにくいかもしれないところをできるだけ簡単に解説しようと思います。
...そのため、C言語の解説書等が手元にあることを前提でC言語の仕様などの面倒な部分は端折ることが多々あると思います。
また正しくない記述もあるかもしれませんがご了承ください。
このページのサンプルプログラムはWindows10 + MinGW(GCC)で行っています。
MinGWに付属するgccのバージョンは 6.3.0 です。
エディタは TEditorMX をお使いいただけると嬉しいです。
解説一覧
(1)変数と型
(2)配列変数とポインタ
(3)構造体
(4)共用体
(5)ポインタのポインタ
(6)関数と関数へのポインタ
(7)割り込みとvolatile
(1)変数と型
C言語の主な変数の型は、
| 型 | サイズ(バイト) | |
|---|---|---|
| void | 0 | |
| 整数 | char | 1 |
| short | 2 | |
| long | 4 | |
| int | 4(32bitCPUの場合) | |
| 実数 | float | 4 |
| double | 8 |
です。整数型変数には unsigned char のように unsigned を付けると符号なし正数になります。
int型はCPUにより、またはコンパイラにより変化します。
移植するときのことを考えた場合の話ですが、int型は使用しない方が無難です。
int型はCPUにより、またはコンパイラにより変化してしまいますので、私はint型はできる限り使用しないようにしています。
C言語では変数を使用する前に宣言をしなければなりません。
宣言する場所は、関数の開始括弧 { の直後に記述するのが基本です。
...が、コンパイラによっては他のところに記述してもOKな場合があります。
詳細はコンパイラ付属のマニュアルやサンプルプログラムなどをご参照ください。
なお、移植のことを考慮する必要があるときは基本を守った方が良いと思います。
変数の宣言の例
int func( void ) // func関数
{ // この開始括弧の直後に変数の宣言を記述するのが基本です。
char c;
short s;
・
・
・
関数の開始括弧以外にも以下の様に途中に記述することができます。
デバッグコードを埋め込む場合などには重宝します。
//#define DEBUG_CODE // コメントを外して有効にするとデバッグコードがコンパイルされます
int func( void ) // func関数
{ // この開始括弧の直後に変数の宣言を記述するのが基本です。
char c;
short s;
・
・
・
#ifdef DEBUG_CODE // デバッグコード開始(DEBUG_CODEを#defineしておくとコンパイルされます)
{ // ← この括弧の直後にローカル変数を宣言できます(大抵のコンパイラで問題なく使えると思います)
char msg[100]; // ローカル変数(配列変数)
wsprintf( msg, "デバッグ用メッセージ\n" );
printf( msg );
}
#endif // デバッグコード終了
// ここでは { } の範囲外なのでmsgにはアクセスできません
・
・
・
定数(固定値)を持つ変数を定義するときには const を用います。
const char c = 1; const short s = 65535;
パソコンなどのRAMしか使用しないシステムの場合には const を用いなくても問題無く動作すると思いますが、
組み込み用システム(ファームウェア)を作成するときには const を使用して宣言しないとROM(固定値を持つ変数なのでSRAMではなくROMに割り当てしなければなりません)
の領域に割り当てられず、正しい結果が得られません。
(2)配列変数とポインタ
配列変数は変数と型で示した型を用いて宣言します。
配列変数の宣言例
char c[100]; // ①char 型の1次元配列で要素数は100個です。確保されるメモリは100バイトです。 short s[2][50]; // ②short 型の2次元配列で要素数は2×50個です。確保されるメモリは200バイトです。 const long l[] = {1,5,10,20,50,100}; // ③long 型の1次元配列です。定数を持ちます。
①は char 型の1次元配列です。割り当てられるメモリは100バイトです。
②は short 型の2次元配列です。割り当てられるメモリは200バイトです。
③は long 型の1次元配列ですが、定数を持ちます。定数は6個ですので割り当てられるメモリは合計24バイトです。
配列は同じ型のデータがメモリ上に連続して並んでいるだけのものです。
配列変数はその並んでいるデータの先頭アドレスを保持してるだけです。つまり配列変数は固定値です。
それに対しポインタはアドレスを保持する変数で、保持するアドレス値は可変です。
配列変数とポインタの大きな違いは保持しているアドレス値が固定値か可変値かというだけです。
そのためポインタは(下のサンプルプログラムでもやっていますが)配列と同じ書き方をすることもできます。
ただし、そうすると配列なのかポインタなのか区別しにくくなりますのでポインタはポインタとしての書き方(* アスタリスクを付ける)をした方が良いと思います。
以下のサンプルプログラム(sample1.c)をコンパイルして実行してみて下さい。
#includeint main( int argc, char *argv[] ) { int lp; long arr[] = {1,2,3,4,5,0}; long *p, *pinc; printf( "arr配列変数の値(addr) = %x\n\n", arr ); p = pinc = arr; for( lp = 0; arr[lp]; lp++ ) { printf( "arr[%d] addr = %x, p[%d] addr = %x, *(p+%d)addr = %x, pinc addr = %x\n", lp, &arr[lp], lp, &p[lp], lp, &(*(p+lp)), pinc ); pinc++; } return( 0 ); }
上のプログラムをgccでコンパイルして実行した結果の例です。
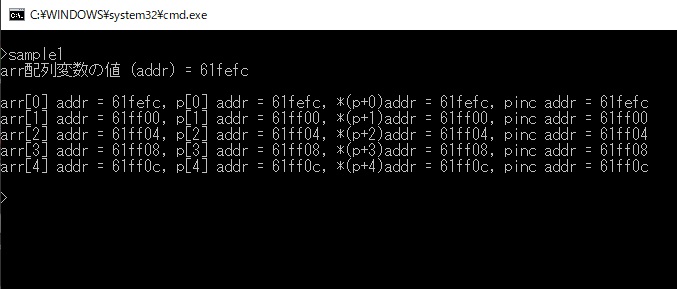
注目して頂きたいのはプログラムでは異なる変数、
または書き方が異なるもの同士ですがアドレス値(= に続く数値)は同じになっているというところです。
同じ型で同じアドレス値を持つ変数(ポインタまたは配列)でアクセスすると同じ値が取得できる...ということです。
これって実は当たり前の話(同じメモリの値を読み込んでいるので)なのですが、プログラムで表現すると分からなくなってしまうことがあります。
分からない方はよ~く考えてみて下さいね。
もう一点、一つ一つの増加しているアドレス値を注意してご覧下さい。
4バイトずつ増加しているのがお分かり頂けるでしょうか?。
これは型のサイズ分{この例では long型(4バイト)}増加しています。
これも重要なポイントです。
(3)構造体
構造体は「型の異なるデータの配列」のようなものですが、
普通の配列と異なるのは番号で管理するのではなくデータ一つ一つに任意の名前を付けて管理します。
構造体の定義例
typedef struct {
char x; // X座標
char y; // Y座標
short data; // データ
} POINTDATA;
安易な例ですが、このように定義します。
structは構造体の定義を表しますが、typedef を付けて POINTDATA のように定義すると
普通の型のように、宣言するときに使用することができます。
最後のセミコロン ; を忘れないで下さい。
typedefの詳細については私は正しく理解できていませんが、この程度を理解していれば実用上は問題ないと思います。
構造体の宣言と使い方の例
POINTDATA pd; // 構造体の宣言(typedefしておけば普通の型と同じように宣言で使用できます!) char x,y; // 変数の宣言 short s; // 〃 ・ pd.x = 1; // 以下、使い方の例 pd.y = 2; pd.data = 3; ・ ・ ・ x = pd.x; y = pd.y; s = pd.data; ・ ・ ・
上記の例の構造体pdは値を持ちます。なんの値を持つか...そう、アドレスです。
...ということは構造体もポインタを使ってアクセスできます。
POINTDATA pd; POINTDATA *lpPd; ・ lpPd = &pd; lpPd->x = 1; lpPd->y = 2; lpPd->data = 3; ・ ・ ・
ポインタを使ってメンバにアクセスするときは ->
を使って普通の構造体のときと同じ感じで行うことができます。
(4)共用体
共用体は「宣言の仕方」と「書き方」に関しては構造体と同じような感じになります。
しかし、決定的に違うところがあります。
それは構造体はメンバ変数すべてに対してメモリを割り当てる(普通ですよね?)のに対して
共用体は一番大きなメンバ変数のサイズしかメモリが割り当てられません。
つまり、共用体は『メモリを共用』するのです。
...でも『そんなもの何に使うの?』という疑問がでてきますよね?。
共用体は構造体と一緒に使うことで意味を持ちます。
共用体と構造体を使ったプログラム(sample2.c)
#include <stdio.h>
typedef struct {
unsigned char b1;
unsigned char b2;
unsigned char b3;
unsigned char b4;
} BYTE_DATA;
typedef struct {
unsigned short s1;
unsigned short s2;
} SHORT_DATA;
typedef union {
unsigned long long_data;
BYTE_DATA byte_data;
SHORT_DATA short_data;
} LONGDATA;
int main( int argc, char *argv[] )
{
LONGDATA lng;
lng.long_data = 0x87654321;
printf( "long_data = %x\n", lng.long_data );
printf( "s1 = %x, s2 = %x\n", lng.short_data.s1, lng.short_data.s2 );
printf( "b1 = %x, b2 = %x, b3 = %x, b4 = %x\n",
lng.byte_data.b1, lng.byte_data.b2, lng.byte_data.b3, lng.byte_data.b4 );
return( 0 );
}
上記のプログラムを実行すると下画像のようになります。
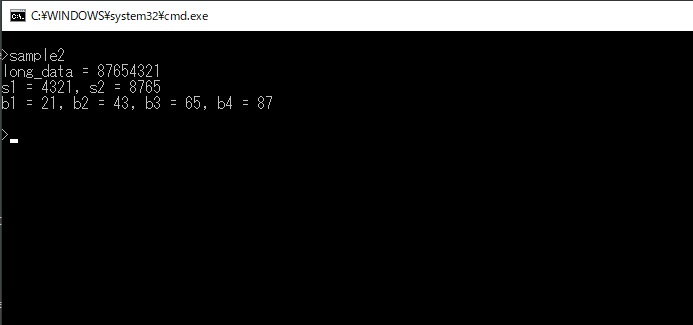
実行結果のご説明をします(インテル系CPUはリトルエンディアンです)。
s2, s1はlong型の上位ワードと下位ワードになっています。
s2が上位ワード(0x8765)、s1が下位ワード(0x4321)です。
b4~b1はlong型の最上位バイト(b4)~最下位バイト(b1)になっています。
b4(0x87), b3(0x65), b2(0x43), b1(0x21)です。
お分かり頂けると思いますが共用体(LONGDATA)で定義した構造体メンバと
unsigned long型変数が使用するメモリの最大値が4バイトで各メンバが参照するメモリが共用されています。
...で、何に使えるのか...ということですが、
具体的な例を挙げますと、例えば関数の戻り値は1つしか返せませんが戻り値として2つ以上返したいことがあったとします。
そんなときにこの共用体を用いますとshort型2つ以下、またはchar型4つ以下なら1つのlong型の戻り値を返すことで
呼び出し側で複数の戻り値に戻すことが可能になります。
共用体は1つのデータを複数に分けて操作したい、または逆に複数のデータをひとまとめで操作したいときに役立ちます。
(5)ポインタのポインタ
ポインタのポインタといってもポインタに変わりはありません。
『ポインタが指し示すアドレスに格納されているデータがポインタです』といっているだけです。
ポインタは変数なのでメモリが確保されていてそのメモリの中に入っているデータがアドレスです。
ポインタのポインタも変数なのでメモリが確保されていてそのメモリの中に入っているデータが
更に次のポインタのアドレスになります。
ポインタのポインタプログラム(sample3.c)
#include <stdio.h>
int main( int argc, char *argv[] )
{
char c;
char *p, **pp;
p = &c;
pp = &p;
c = 1;
printf( "&c = %x, c = %d\n", &c, c );
printf( "p = %x, *p = %d\n", p, *p );
printf( "pp = %x, *pp = %x, **p = %d\n", pp, *pp, **pp );
return( 0 );
}
実行結果は下画像のようになります。
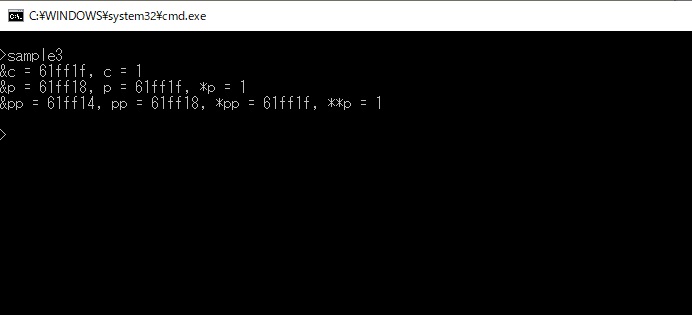
cの実体(アドレス)は61ff1fになっています。
pの実体(アドレス)は61ff18で、そのアドレスの中身はcの実体(アドレス)が格納されています。
ppの実体(アドレス)は61ff14で、そのアドレスの中身はpの実体(アドレス)が格納されています。
ここまで、難しくないですよね?
で、こんなもの何に使えるの?ということですが...例えば、プログラムのmain関数の引数を参照するのに使えます。
下のプログラム(sample3a.c)はコマンドラインで渡された引数を表示するものです。
ポイントは引数のポインタ配列(argv:ポインタの1次元配列)をポインタのポインタ(pp)を使って参照しているところです。
配列変数とポインタ変数の違いは変数に格納されている値(アドレス値)が『固定値』か『可変値』かだけです。
なのでポインタ配列をポインタのポインタで参照することができます。
#include <stdio.h>
int main( int argc, char *argv[] )
{
int lp;
char **pp;
pp = (char **)argv;
if( argc <= 0 ) {
printf( "引数が異常です。\n" );
} else {
printf( "引数の数 = %d\n", argc );
for( lp = 1; lp <= argc; lp++ ) {
printf( "第%d引数 = %s\n", lp, *pp++ );
}
}
return( 0 );
}
実行結果は下画像のようになります。

(6)関数と関数へのポインタ
C言語の『関数」とはサブルーチンのことです。
「引数」を渡して「戻り値」を得るという数学の『関数』のような使い方もできますし、
グローバル変数を操作することで結果を得るような使い方もできます。
この辺はプログラマ次第ですのでできるだけ分かりやすく作れれば良いと思います。
関数はサブルーチンです。サブルーチンを呼び出すときはアドレスを指定する必要があります。
...アドレスを指定する...つまり、関数もポインタを使って呼び出せるってことです。
それが『関数へのポインタ』です。
関数へのポインタのサンプルプログラム(sample4.c)
#include <stdio.h>
void test_func( void )
{
printf( "test_func\n" );
}
int main( int argc, char *argv[] )
{
void (*p)(); // ポインタのポインタを宣言
p = test_func; // ポインタにtest_funcのアドレスを代入
p(); // 関数へのポインタを使ってtest_funcを呼び出し
return( 0 );
}
実行すると直接は呼び出していないtest_funcが実行され 'test_func' という文字列が表示されます(下画像)。
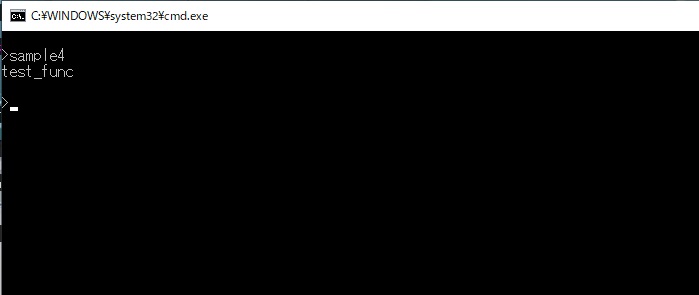
これは私の個人的な意見ですが、関数へのポインタは宣言が複雑になりやすく仮に正しい宣言を記述したとしてもコンパイラが正しく理解してくれずにエラーになったりすることがあります。 そのため関数へのポインタを使うときはできるだけシンプルに(この例のように引数、戻り値をvoidにするとか)した方が良い結果が得られるのではないかと思います。 引数無し、戻り値無し...ということはすべてグローバル変数から必要なデータを受け取り、結果を返すということになります。
(7)割り込みとvolatile
割り込みルーチンをC言語で記述する場合に1つだけ気を付けなければいけないことがあります。
大抵のコンパイラは最適化処理ができて変数はレジスタに割り当てられてしまい、常にメモリから読み出されるわけではありません。
これが割り込み処理に適用されてしまいますと割り込みルーチンで書き換えたはずの変数の値がメインルーチン側で正しく反映されずに上手く動作しないということが起こります。
そこで登場するのが volatile です。これを宣言するときに付けておくと最適化処理を抑えて常にメモリから変数の値を読み込むようになり、正常に動作するようになります。
volatile の使い方
volatile short s; // グローバル変数を宣言 volatile long lng;
のように、グローバル変数を宣言するときに使います。
割り込み処理中に値を書き換えるグローバル変数を宣言するときには volatile を付ける...と覚えておけば大丈夫だと思います。
以上、私がC言語を学ぶときにハマったところをざっと解説させて頂きました。
極力簡単に分かりやすくサンプルプログラムも掲載してご説明させて頂いたつもりですがいかがでしたでしょうか?
ちょっとでもあなたのお役に立てることができたら嬉しいです。
以上です。